

Happy Monday! ☀️
Welcome to the 144 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
ClickHouse celebrates ten years thriving in open source
CQRS without complexity: split read-write paths elegantly
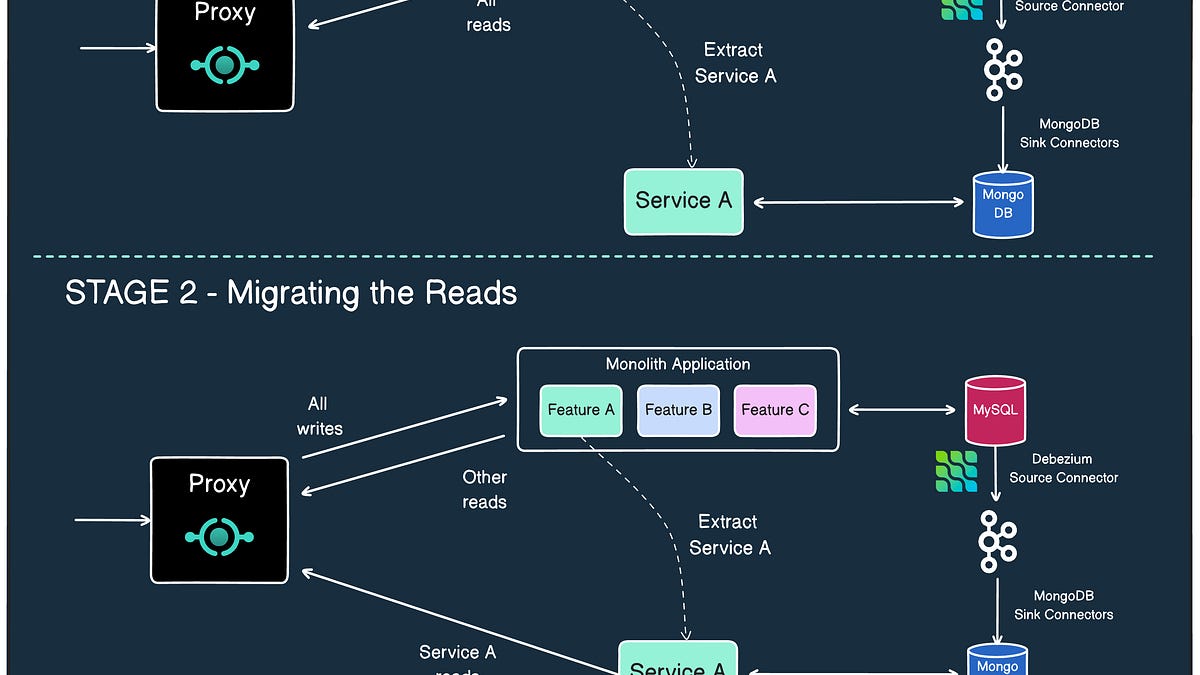
Monolith to services: scaling architecture patterns explained
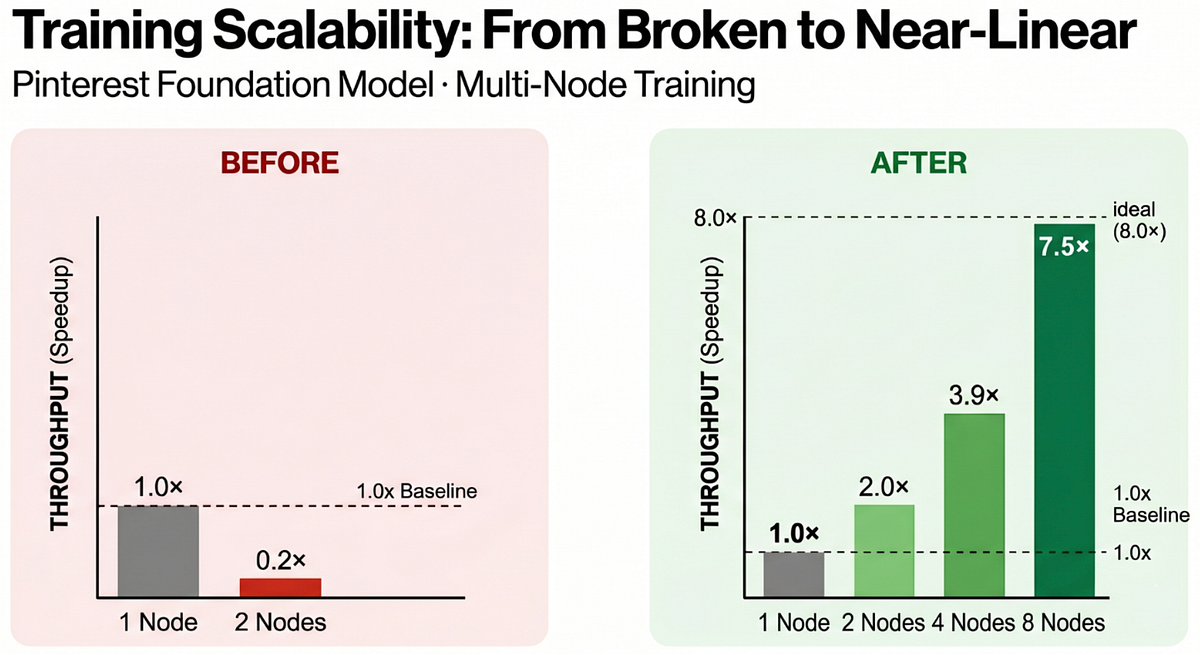
Pinterest's foundation models achieve near-linear training scalability
Six SQL fraud patterns catch transaction anomalies instantly
🗞️ Tech and AI Trends
OpenAI's custom chip built with Broadcom arrives
Chinese AI models narrow the gap significantly
Open weight models become unbearably cheap now
👨🏻💻 Coding Tip
Prevent cache stampedes with probabilistic early revalidation and background refresh queues, spreading load smoothly
Time-to-digest: 5 minutes

DoorDash engineer Ivar Lazzaro spent months wrestling with AI agents before cracking the code: getting Claude to autonomously ship multi-thousand-line features. His journey went from Cursor productivity wins to expensive AI "slop" to finally nailing a framework that actually works at scale.
The challenge: Long-running agents lose coherence mid-task, contradict themselves across context windows, and can't self-review worth a damn. You need a system that survives the probabilistic nature of LLMs.
Implementation highlights:
Research → Plan → Implement phases: Break work into distinct cognitive phases with concrete artifacts between each. The agent researches reality first (not the solution), then plans with specific file paths and acceptance criteria, then implements against that plan—not a half-forgotten spec.
The antagonistic reviewer pattern: Never let the agent that wrote the code be its only judge. A fresh context window reviewer catches mistakes the implementer defended with narrative momentum.
Progress files as long-term memory: Agents are stateless and forget things. Persist a progress file that says "here's what I've done, here's what's left" so fresh context windows can pick up mid-task without losing continuity.
The loop with retry semantics: When an agent hits context limits or gets stuck, emit
AGENT_LOOP_STATUS: RETRY, spin up a fresh session with clean context, hand it the progress file, and let it continue. Simple aswhile [ iteration < max_iterations ].Boring deterministic orchestration: Build a state machine that enforces phase transitions, isolates features in git worktrees, manages sessions, and recovers from crashes. The harder the agents become, the more valuable a predictable harness around them.
Results and learnings:
It actually ships: Built a fully functional 2D retro game maker with level editor, sprite editor, and playable test mode in 12 hours, zero human hand-holding (just $250 in API costs).
The loop scales: Handle multiple concurrent features without context-switching between terminals. One dashboard, persistent state, deterministic workflows.
Your brain is the real bottleneck: Productivity doesn't mean fewer hours—it means denser hours. More decisions per minute, higher cognitive load, mental fatigue creeping in. The agents don't tire. You do.
Ivar's work proves that AI agents can ship real software autonomously—but not because they're magic. They're amplifiers. Feed them vague prompts, get vague code. Know your systems well enough to ask the right questions, and they'll implement circles around you. The role of the engineer isn't disappearing; it's shifting from writing code to knowing what good code looks like and articulating it clearly.





ARTICLE (brain go brrr then brr)
The Training Trap: Underfitting, Overfitting, and How to Escape Them
ARTICLE (oopsie in the cloud)
StubZero: $148,337 RCE in Google Cloud Production
ESSENTIAL (commit your feelings instead)
Stop using Conventional Commits
ARTICLE (markdown is not code buddy)
Stop Programming in Markdown
ARTICLE (catch the bad number go beep)
Six SQL patterns I use to catch transaction fraud
ARTICLE (privacy go hide hide)
Privacy-Aware Infrastructure in the AI-Native Era: An Asset Classification Case Study
ARTICLE (bucket talks computer noises)
I taught a bucket to speak git
ARTICLE (cassandra go zoom zoom)
The Evolution of Cassandra Data Movement at Netflix
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: Elon Musk confirmed Starmind as SpaceX's planned 1-million AI satellite constellation, running inference in orbit with solar power and vacuum cooling, with prototypes launching early 2027 and Musk projecting space becomes the lowest-cost AI compute location within 2-3 years.
Brief: Despite Figma's market cap crashing below $10B on AI-loser narratives, Field argues AI is TAM-expansive for design, unveiling Code on the Canvas, Motion, and shaders at Config to merge design and code into one collaborative surface while warning AI-induced "tunnel vision" is killing design teams.
Brief: OpenAI debuted Jalapeño, an inference-only processor co-designed with Broadcom and partly built using its own AI models, claiming significantly better performance-per-watt than current GPUs as it pushes to reduce Nvidia dependence and optimize the full stack.
Brief: DeepSeek V4 runs at roughly 1/50th the token cost of Anthropic and OpenAI's frontier models, raising fears that US labs will manufacture scarcity through China-fear lobbying rather than competing, while truly open-source projects like Allen AI's OLMo point to a different path.
Brief: Z.ai's open-source GLM-5.2 lands within a percentage point of Anthropic's Opus 4.8 on key agentic benchmarks at one-fifth the cost, with six of the top AI leaderboard models now Chinese as US firms face Trump-era access restrictions and businesses hunt for cheaper inference.
Brief: Sam Altman told staff the US government wants GPT-5.6 released customer-by-customer to vetted partners first, following a June executive order giving officials a 30-day frontier model review window and arriving two weeks after Anthropic was forced to pull Mythos 5 and Fable 5 globally.

This week’s tip:
Implement cache stampede prevention with probabilistic early revalidation and a background refresh queue. Instead of thundering-herd cache misses, continuously refresh keys before expiry using exponential backoff on revalidation failures.

Wen?
High-QPS API gates: Probabilistic early refresh spreads revalidation load smoothly across the TTL window, preventing the spike when millions of keys expire simultaneously.
Popular content bursts: During traffic spikes (e.g., trending topic), background refresh keeps hot keys fresh without cache misses triggering cascading origin hits.
Downstream circuit breaking: Combine with exponential backoff on upstream failures; if revalidation fails, return stale data longer and retry less frequently, protecting the origin.
Luck is what happens when preparation meets opportunity. Seneca


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).