

Happy Monday! ☀️
Welcome to the 256 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
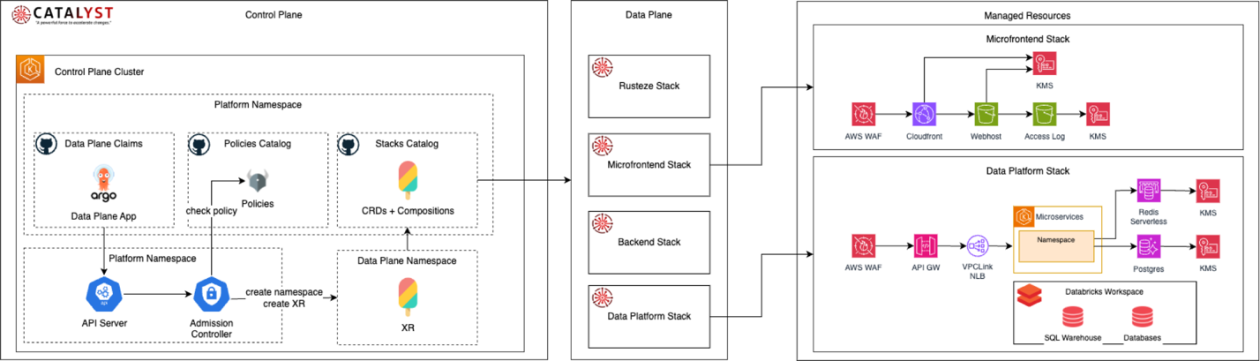
Santander's platform engineering revolutionizes cloud infrastructure at scale
Software engineering productivity evolution: what's actually changed?
Cloudflare redesigned Turnstile, the internet's most-seen UI
Netflix's MediaFM multimodal AI powers media understanding
RabbitMQ vs Kafka vs Pulsar: choosing your message broker
🗞️ Tech and AI Trends
Global intelligence crisis looms in 2026 with major implications ahead
Block cuts 4,000 jobs, over 40% of workforce
Google restricts OpenClaw usage on AI Pro subscribers
👨🏻💻 Coding Tip
CSS cascade layers (@layer) eliminate !important wars and let Tailwind coexist with custom components cleanly.
Time-to-digest: 5 minutes

Mixture of Experts (MoEs) are reshaping how we build LLMs. Instead of scaling everything densely, MoEs activate only a subset of experts per token, delivering massive model capacity while keeping inference fast and efficient. But getting them to work smoothly in production requires rethinking how we load weights, route tokens, and distribute computation.
The challenge: MoE models break assumptions built into the entire ecosystem. Checkpoints serialize experts separately, but GPUs need them packed contiguously. Routing billions of tokens efficiently requires specialized kernels. Scaling across devices demands a completely different parallelization strategy than traditional tensor parallelism.
Implementation highlights:
Weight loading refactor with
WeightConverter: Transform checkpoint tensors into optimized runtime layouts on-the-fly using composable operations likeMergeModulelistandSplitModulelistLazy materialization pipeline: Load and convert weights asynchronously with dependency tracking, reducing memory peaks and repeated scans
Pluggable experts backend: Decouple expert execution from model code via a decorator pattern, supporting
eager,batched_mm, andgrouped_mmstrategies for different hardware constraintsExpert parallelism with smart sharding: Distribute experts across devices using
GroupedGemmParallelandRouterParallel, remapping indices and using all-reduce for result aggregationUnsloth integration for training: Leverage
torch._grouped_mm+ custom Triton kernels to achieve 12× faster training and 35% VRAM reduction
Results and learnings:
3.2× faster loading: Qwen1.5-110B loads in 20.7s (v5 async) vs 66.2s (v4), crushing previous bottlenecks
Framework-agnostic routing: Three pluggable backends let you optimize for memory, batch size, or raw throughput without changing model code
Production-ready at scale: DeepSeek V3 (256 experts), Qwen 3.5, and GPT-OSS models now run smoothly on consumer and enterprise hardware
Hugging Face's approach proves that sparse architectures don't require sacrificing developer experience. By treating weight loading as a conversion pipeline rather than a key-by-key copy, they've solved one of LLM's messiest problems. Smart abstractions compound—the weight converter pattern enables quantization-aware loading, expert parallelism becomes a config flag, and training becomes tractable again.



ARTICLE (brain juice for robots)
How Large Language Models Learn
ARTICLE (streams go whoooosh)
We deserve a better streams API for JavaScript
ARTICLE (next-gen speedrun)
How we rebuilt Next.js with AI in one week
ARTICLE (containers go brrrr)
Mount Mayhem at Netflix: Scaling Containers on Modern CPUs
ARTICLE (queue wars royale)
EP203: RabbitMQ vs Kafka vs Pulsar
ARTICLE (ai ninja squad vibes)
How OpenAI's Codex Team Works and Leverages AI
ARTICLE (time is a social construct)
Your Hours Worked Don't Matter
ARTICLE (sandbox shenanigans)
Run OpenClaw Securely in Docker Sandboxes
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: Despite massive AI spending and data center construction, real adoption data shows stable, non-exponential growth in workplace AI use, while software engineer job postings are rising—suggesting AI will complement rather than replace labor, with productivity gains historically expanding demand instead of collapsing it.
Brief: Jack Dorsey announces Block is laying off over 4,000 employees — nearly half its workforce — to capitalize on AI-driven efficiencies, citing the need for smaller teams powered by intelligence tools; the stock surged 25% after hours as Wall Street views the move as decisive leadership, with the company targeting a 4x jump in gross profit per employee.
Brief: Despite headlines predicting developer obsolescence by 2026, enterprise environments move far slower than Twitter suggests—rigid approval processes, compliance requirements, and security concerns in finance, healthcare, and manufacturing will ensure human developers remain essential for years to come.
Brief: Multiple Google AI Ultra subscribers report sudden account restrictions without prior warning, with some locked out entirely after connecting third-party OAuth integrations like OpenClaw; users cite days of silence from support and frustration with being passed between Google Cloud and Google One support teams.
Brief: Sam Altman announces OpenAI has reached an agreement with the Department of War to deploy their AI models on classified networks, with built-in safeguards against domestic surveillance and autonomous weapons, while calling on the DoW to extend the same safety terms to all AI companies.
Brief: MIT researchers developed an AI-driven framework that identifies which cellular data are shared across different measurement modalities and which are unique to specific techniques, giving scientists a holistic view of cell state that could accelerate understanding of cancer, Alzheimer's, and diabetes.

This week’s tip:
Master CSS cascade layers @layer) to enforce stylesheet precedence without !important, allowing third-party libraries and utility frameworks (Tailwind) to coexist with component styles. Layers are evaluated in declaration order, enabling predictable specificity management.

Wen?
Tailwind + custom components: @layer components before @layer utilities guarantees Tailwind classes override component defaults without specificity wars.
Design system migrations: Layers allow old SASS architecture (scoped components) to gradually coexist with atomic CSS; developers never resort to !important.
Third-party CSS isolation: @layer external { /* vendor CSS */ } ensures vendor styles don't inadvertently override application utilities via specificity tricks.
Always do your best. What you plant now, you will harvest later.
Og Mandino


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).