

Happy Monday! ☀️
Welcome to the 879 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
Building the foundation for running extra-large language models
Securing every Kubernetes workload at scale
Netflix's operations layer behind live at scale
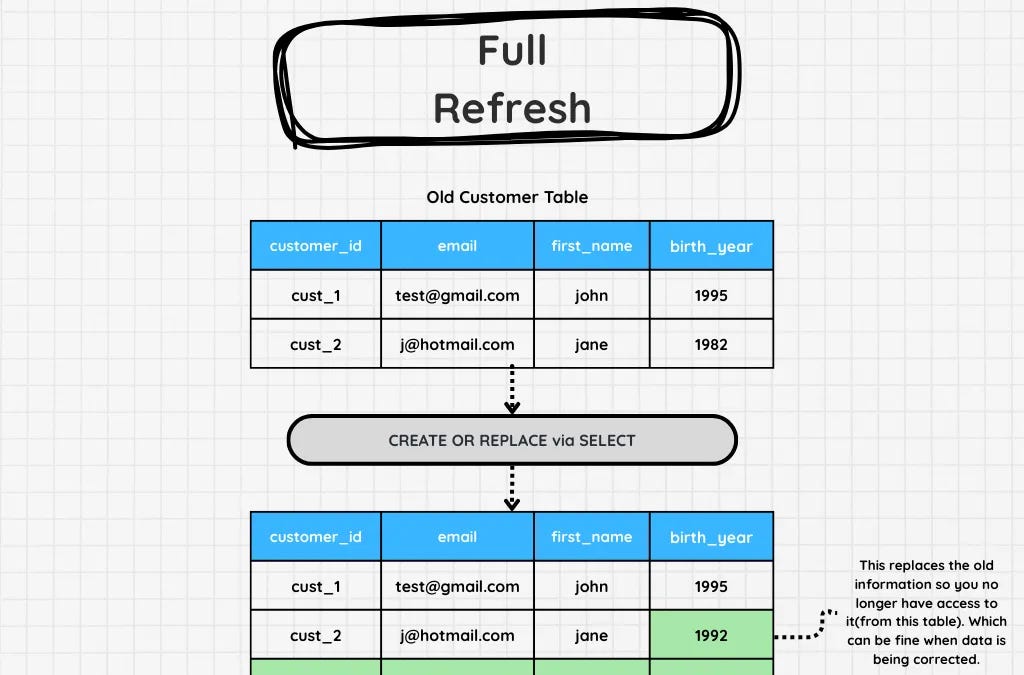
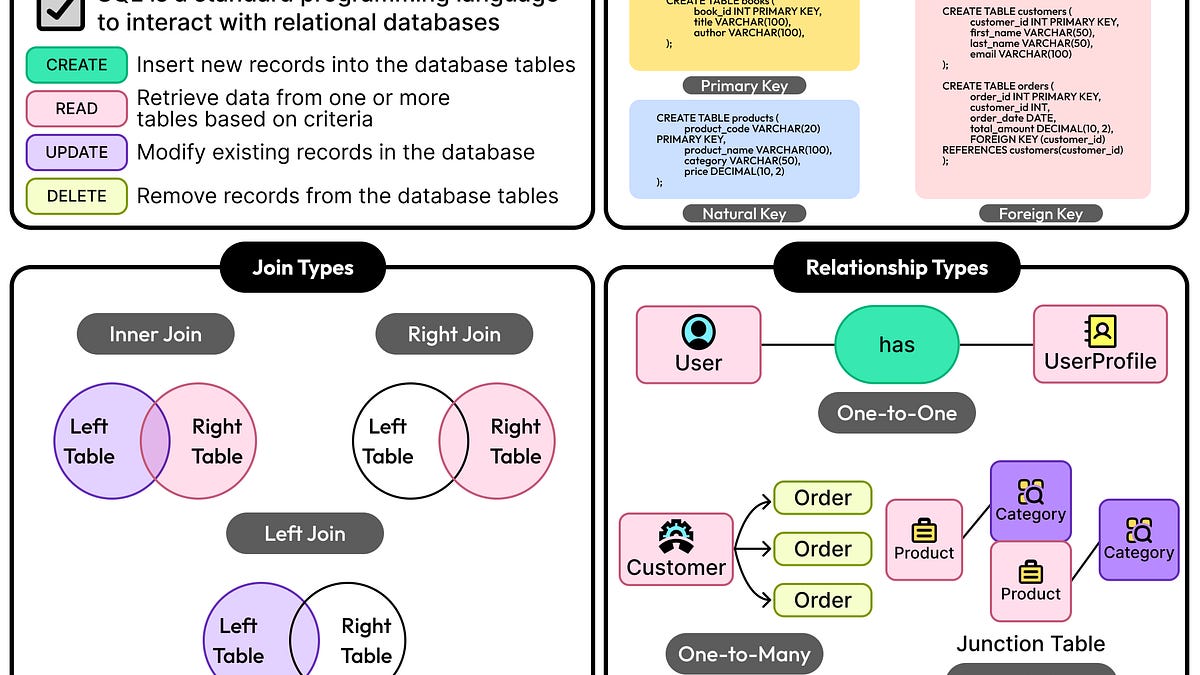
Relational database design guide: master the fundamentals
Why MicroVMs power Docker's sandbox architecture
🗞️ Tech and AI Trends
Google opens Gemma 4 under Apache 2.0 with multimodal capabilities
Claude Opus 4.7 released: faster reasoning, better performance
Zero-copy GPU inference from WebAssembly on Apple Silicon
👨🏻💻 Coding Tip
React Server Components eliminate client-side data fetching, reduce bundle size dramatically
Time-to-digest: 5 minutes

NVIDIA's OCR v1 model was solid for English but completely fell apart on other languages; we're talking 0.56 to 0.92 NED scores (basically gibberish). Instead of manually annotating millions of images across six languages, they went all-in on synthetic data generation and built Nemotron OCR v2.
The challenge: Train a single unified OCR model that handles English, Chinese, Japanese, Korean, and Russian without language-specific variants — and do it without the prohibitive cost of annotating millions of real-world images with word-, line-, and paragraph-level bounding boxes.
Implementation highlights:
Synthetic data pipeline: Generate 12.2M training images with pixel-perfect ground truth by rendering text from mOSCAR (a 163-language web corpus) onto randomized backgrounds with diverse fonts, layouts, and augmentations
Hierarchical annotations for free: Every synthetic image comes with word, line, and paragraph bounding boxes plus a reading order graph — labels that would cost a fortune to annotate manually
Line-level recognition for CJK: Chinese and Japanese don't use spaces between words, so they switched from word-level to line-level recognition — eliminating the need for a separate word segmentation step
Shared backbone architecture: Based on the FOTS design, a single RegNetX-8GF backbone processes the image once, then detection, recognition, and relational models all reuse those features — no redundant computation
Language-agnostic extensibility: Adding a new language only requires source text + fonts. No architecture changes, no manual annotation. The pipeline generates millions of annotated pages per day on a single machine
Results and learnings:
From gibberish to near-perfect: NED scores on non-English languages dropped from 0.56–0.92 down to 0.035–0.069 — a single model outperforming even language-specific competitors
Absurdly fast: 34.7 pages/second on a single A100 GPU, 28x faster than PaddleOCR v5's server pipeline
Data > architecture: Expanding the character set alone barely helped. The model could theoretically output CJK characters — it just had never learned what they looked like
NVIDIA's approach is a masterclass in letting synthetic data do the heavy lifting. If you can programmatically generate your labels, you skip the most expensive part of ML; and you get to control exactly what your model sees during training. The dataset and model are both open, so you can extend this to your own languages today.




ARTICLE (design-code-tango)
Figma Design to Code, Code to Design: Clearly Explained
GITHUB REPO (stack-em-high)
Stacked PRs
ARTICLE (math-goes-brrr)
All elementary functions from a single binary operator
ARTICLE (protocol-party-time)
Scaling MCP adoption
ARTICLE (money-moves-smooth)
Engineering the Forge Billing Platform for Reliability and Scale
ARTICLE (tile-time-magic)
Frontend Engineering at Palantir: Polar Scaled Tiles in Zodiac
ARTICLE (robot-future-vibes)
The Agent Stack Bet
ARTICLE (slice-it-vertical)
Vertical Slice Architecture in Node.js: One Folder Per Use Case
ARTICLE (gpt-plays-favorites)
Why ChatGPT Cites One Page Over Another
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: Google releases Gemma 4, an open-weight model family with Apache 2.0 licensing spanning 2B-31B parameters, featuring native video, image, and audio processing, 256K context windows, and agentic capabilities like function-calling and structured JSON output—with the 31B variant matching performance of models 3-5x larger and broad distribution across Hugging Face, Kaggle, vLLM, Ollama, and other platforms.
Brief: As open LLM models grow increasingly capable, inference engineering—the practice of optimizing how AI models run in production—is shifting from a niche skill at frontier labs to a critical competency for any company building AI products; key techniques include quantization, speculative decoding, caching, parallelism, and disaggregation to achieve faster, cheaper, and more reliable model serving.
Brief: Anthropic launched Claude Opus 4.7, a significant improvement over Opus 4.6 that excels in advanced software engineering, complex long-running tasks, and vision capabilities—processing images at 3.75 megapixels—while introducing cybersecurity safeguards and new effort control options, available across all Claude products at unchanged pricing.
Brief: Anthropic unveils Claude Design, an AI-powered tool that lets teams collaborate with Claude to create polished designs, prototypes, and presentations by describing what they need, with features like automatic brand consistency, inline editing, and seamless handoffs to code—available now for Claude Pro, Max, Team, and Enterprise subscribers.
🤖 OpenAI Upgrades Codex with Computer Control, Image Generation, and Advanced Developer Tools (4 min)
Brief: OpenAI significantly expands Codex capabilities for its 3M+ weekly users, adding computer control to operate apps, image generation, native web browsing, 90+ new plugins, and memory features to streamline the entire software development lifecycle from coding to deployment.
Brief: A developer demonstrates that WebAssembly modules can share memory directly with Apple Silicon GPUs without copying data, using the chip's unified memory architecture to run stateful AI inference with portable KV caches that can be serialized, restored across machines, and recovered 5.45× faster than recomputation.

This week’s tip:
Use React Server Components (RSCs) with Server Actions to eliminate client-side data-fetching boilerplate and reduce JavaScript bundle size by moving logic server-side. RSCs render on server, stream to client, and support direct database/API access without intermediate API endpoints.

Wen?
Data-heavy dashboards: Fetch and filter data server-side; stream only rendered HTML.
Secure mutations: Run sensitive operations (auth checks, DB writes) in Server Actions; client never sees tokens or credentials.
Progressive enhancement: RSCs work without client JavaScript; add interactivity with 'use client' islands only where needed.
Greatness comes from living with purpose and passion.
Ralph Marston


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).