

Happy Monday! ☀️
Welcome to the 151 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
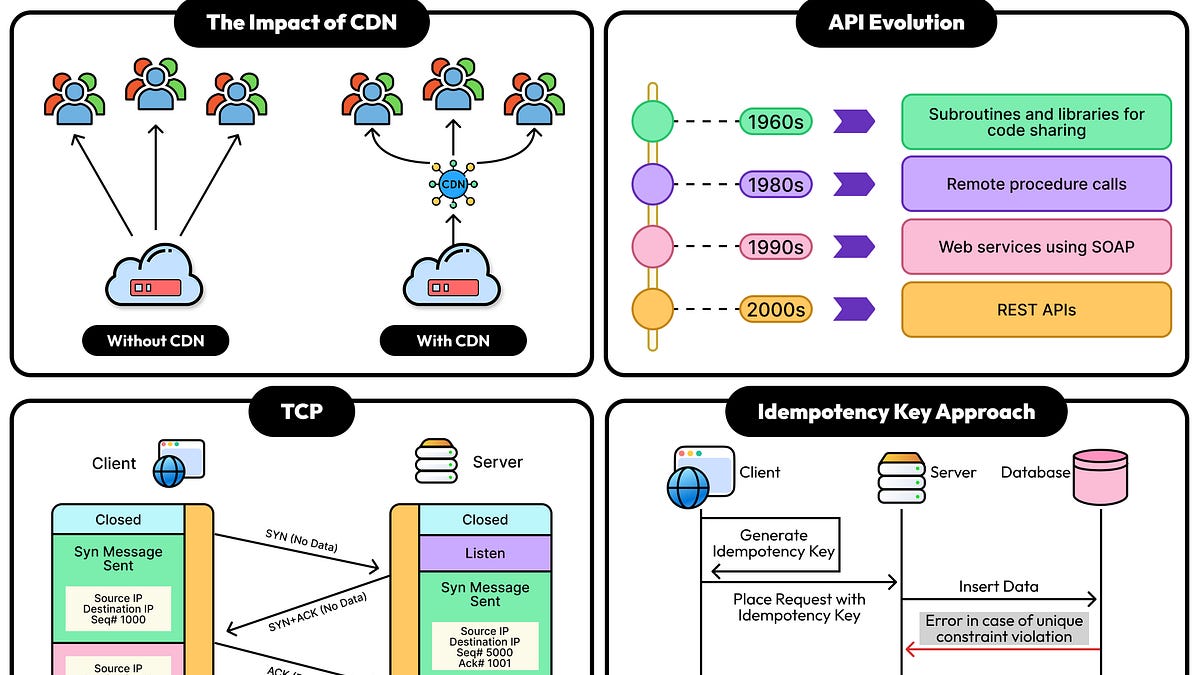
Master distributed systems fundamentals every engineer should know
Inside look at AWS S3's architecture and scalability secrets
Airbnb's system design decoded: architecture and scaling decisions
Learn 20 DSA patterns to ace technical interviews
Use storytelling to accelerate your tech career growth
🗞️ Tech and AI Trends
OpenAI's hardware plans revealed with Apple veterans joining
Epic secures $800M deal with Google for Unreal Engine
Musk demands $134B from OpenAI and Microsoft
👨🏻💻 Coding Tip
BRIN indexes save storage space in PostgreSQL time-series data queries
Time-to-digest: 5 minutes

OpenAI runs ChatGPT on a single PostgreSQL primary instance with nearly 50 read replicas spread globally. Their database load grew 10x in one year. Instead of rushing to shard, they pushed Postgres to its absolute limits—and it worked.
The challenge: Scale a single-writer architecture to handle millions of QPS while surviving traffic spikes, cache storms, and the occasional viral feature launch that brings 100M new users in a week.
Implementation highlights:
Aggressive read offloading: Route all possible reads to replicas, keeping the primary lean and ready for write spikes—even critical requests survive if the primary goes down
PgBouncer connection pooling: Cut connection setup time from 50ms to 5ms using statement/transaction pooling, co-locating proxies with replicas to minimize network overhead
Cache locking for miss storms: When cache fails, only one reader fetches from Postgres per key—everyone else waits for the cache to repopulate instead of hammering the DB
Workload isolation by priority: Split traffic into high/low priority tiers on separate instances so a noisy neighbor can't tank your critical path
Cascading replication (in progress): Let intermediate replicas relay WAL to downstream nodes, scaling to 100+ replicas without crushing the primary's network
Results and learnings:
Blazing performance: Low double-digit ms p99 latency with five-nines availability in production
Battle-tested resilience: Only one SEV-0 Postgres incident in 12 months—during the ImageGen viral launch
Future-proofed: Migrated write-heavy workloads to CosmosDB, keeping Postgres focused on what it does best
OpenAI's story proves you can scale Postgres way further than most people think—if you obsess over query optimization, isolate workloads, and protect against cascading failures. Sharding isn't always the answer; sometimes it's just rigorous engineering.
Turns out the secret to handling 800 million users is treating your database like a celebrity: keep the crowds away, give it plenty of bodyguards, and never let it do its own heavy lifting. 🐘




ARTICLE (robot breakdown)
Agent Psychosis: Are We Going Insane?
GITHUB REPO (zen-bot-vibes)
Claude Chill
ESSENTIAL (future-proof-yourself)
LLMs and your career
ARTICLE (helper-junkie)
I'm addicted to being useful
ESSENTIAL (algo-whisperer)
DSA was HARD until I Learned these 20 Patterns
GITHUB REPO (quick-maths)
Napkin math
ARTICLE (apache-hudi)
Uber scaling hudi
ARTICLE (ai-needs-humans)
Why AI coding tools shift the real bottleneck to review
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: OpenAI hints at upcoming hardware product collaboration with former Apple design chief Jony Ive, while his firm LoveFrom continues to recruit Apple veterans for the secretive project.
Brief: Judge reveals $800M partnership between Epic and Google involving Unreal Engine licensing and joint marketing, with Epic spending the amount on Google services over 6 years, raising questions about its influence on their recent antitrust settlement.
Brief: Internal documents reveal how Microsoft evolved from missing OpenAI's launch to becoming its key investor with a 27% stake, showing the transformation of their relationship from a simple cloud partnership to a $250B strategic alliance that shaped AI's future.
Brief: Elon Musk files lawsuit seeking up to $134 billion in damages from OpenAI and Microsoft, claiming the AI company betrayed its nonprofit mission by partnering with Microsoft, with trial set for April in Oakland.
Brief: After 20 years, jQuery 4.0.0 launches with major updates including ES modules support, improved CSP compliance, dropped legacy browser support, and a slimmer build while maintaining broad modern browser compatibility.
Brief: Meta's CTO Andrew Bosworth reveals that their Superintelligence Labs team has delivered promising new AI models internally, including potential language and image/video models codenamed Avocado and Mango, following previous Llama 4 delays.

This week’s tip:
PostgreSQL's BRIN indexes provide massive space savings for naturally ordered data by storing min/max values per block range instead of per-row entries. They're ideal for time-series data with correlation between physical and logical ordering.

Wen?
Time-series analytics: Index timestamp columns in IoT or metrics tables with append-only patterns
Audit logs: Efficiently query large audit tables by date ranges with minimal index storage overhead
Partitioned tables: Use BRIN on partition keys when data naturally clusters by the partitioning column
Spend eighty percent of your time focusing on the opportunities of tomorrow rather than the problems of yesterday.
Brian Tracy


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).