

Happy Monday! ☀️
Welcome to the 1245 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
AI-powered UI test generation for iOS apps explained
AWS lessons learned from 3000 incidents
20 software engineering laws you should know
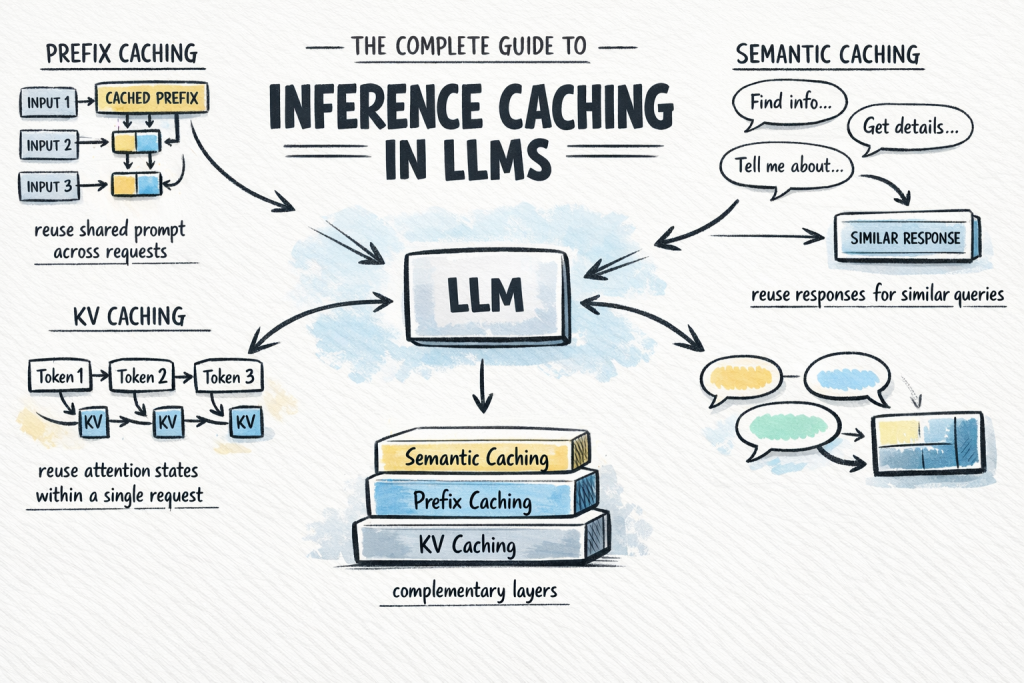
Inference caching in LLMs complete guide
5 silent failures in data pipelines
🗞️ Tech and AI Trends
DeepSeek unveils flagship AI model one year later
OpenAI announces GPT-5.5, latest AI model released
John Ternus becomes Apple CEO as Tim transitions
👨🏻💻 Coding Tip
Use native
<dialog>withshowModal()for accessible, focus-trapping modals without libraries
Time-to-digest: 5 minutes

OpenAI's Codex agent loops dozens of back-and-forth API calls to complete tasks like debugging code. Each request validates, processes, and sends the full conversation history; a massive overhead that was eating latency gains from faster inference speeds. They needed to move the bottleneck away from the API layer.
The challenge: When inference speeds jump from 65 to 1,000 tokens per second, repeated API overhead becomes the wall you hit, not the model. You can't just make each request faster—you need to eliminate redundant work entirely.
Implementation highlights:
Persistent WebSocket connections: Replace synchronous HTTP calls with a single long-lived connection that maintains state across the agent loop lifecycle
In-memory response caching: Store previous response state (tokens, tool definitions, sampling artifacts) on the connection to skip rebuilding full conversation history
Minimal API surface: Use familiar
response.create+previous_response_idInstead of new async patterns; developers integrate without rewriting codeSelective reprocessing: Run safety classifiers and validators only on new input, not the entire conversation history every round
Overlapped execution: Handle non-blocking work (billing, logging) asynchronously while subsequent requests are already processing
Results and learnings:
40% end-to-end speedup: Agent workflows became dramatically faster across Vercel SDK, Cline, and Cursor integrations
Infrastructure matched inference: Hit the 1,000 TPS target for GPT-5.3-Codex-Spark with bursts reaching 4,000 TPS in production
Developer adoption was instant: Zero-friction migration path meant adoption ramped up immediately across the community
OpenAI proved that when your model gets faster, your infrastructure has to get faster too. Smart API design isn't about adding features—it's about removing friction so users actually feel the speed they're paying for.





ARTICLE (ai startup vibes)
How an AI-Native Startup From SF Works and Builds Its Product
ARTICLE (self-care code edition)
Build yourself flowers
ARTICLE (images go squish)
The end of responsive images
ARTICLE (robots do chores)
Agents as scaffolding for recurring tasks
ESSENTIAL (time money brain hurt)
Extreme Time Value of Money: Late-stage Career Planning
ARTICLE (stories go zoom)
Interactive Storytelling for the Web: Building Immersive Stories with Timelines, 3D, and Layered Scenes
ARTICLE (remote dev nest tour)
A Deep Dive into My Remote Development Setup
ESSENTIAL (sql brain juice)
Mastering CTEs in SQL
ARTICLE (data oopsie traps)
The 5 Silent Failures in Data Pipelines
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: China's DeepSeek unveiled its V4 Flash and V4 Pro series, claiming they're the most powerful open-source AI models, featuring improved coding benchmarks, advanced reasoning capabilities, a new Hybrid Attention Architecture for better conversation memory, and a 1 million-token context window that allows entire codebases to be processed as single prompts.
Brief: Meta is laying off 8,000 employees (10% of workforce) starting May 20 and canceling 6,000 open positions as it pivots aggressively toward generative AI to catch competitors like OpenAI and Google, following multiple smaller cuts since January.
Brief: OpenAI unveiled GPT-5.5, its latest AI model excelling at coding, computer use, and research, now rolling out to paid subscribers across ChatGPT and Codex, as the company races to compete with rivals like Anthropic's Claude Mythos amid intensifying competition in the AI sector.
Brief: Amazon is doubling down on AI infrastructure with a $25 billion investment in Anthropic (on top of $8 billion already committed), while Anthropic pledges to spend over $100 billion on AWS services over the next decade and secure 5 gigawatts of capacity for its Claude AI models—a massive power play as tech giants race to build out AI infrastructure.
Brief: Tech companies including Meta, Microsoft, and Salesforce created internal token leaderboards to boost AI adoption, but the gamified competition backfired spectacularly—engineers are now burning billions in tokens on throwaway work just to climb rankings, with Meta alone spending 60.2 trillion tokens monthly (potentially $100M+ in costs) on largely wasteful tasks while only Shopify's approach with circuit breakers and transparent oversight proved effective at avoiding the trap.
Brief: Apple announces Tim Cook will become executive chairman while John Ternus, senior vice president of Hardware Engineering, becomes CEO effective September 1, 2026, following a long-term succession plan that grows the company from $350B to $4 trillion in market cap under Cook's 15-year leadership.
Brief: SpaceXAI and Cursor are partnering to develop advanced coding AI by combining Cursor's AI software platform and engineer user base with SpaceX's Colossus supercomputer (equivalent to a million H100s), with SpaceX holding an option to acquire Cursor for $60 billion later this year.

This week’s tip:
Use the native <dialog> element with showModal() and inert attribute to create accessible, focus-trapping modals without third-party libraries, ensuring proper ARIA semantics and keyboard handling. Browsers automatically manage focus-within-dialog and backdrop interactions.

Wen?
Focus management: showModal() automatically traps focus and restores it on close; no manual tabindex juggling needed.
Form submissions: Using method="dialog" simplifies close handling and value passing to parent scripts.
Multiple modals: Nested dialogs with inert on backdrop content prevent interactive elements outside active dialog from receiving focus.
Your dream has to be bigger than your fear.
Steve Harvey


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).