

Happy Monday! ☀️
Welcome to the 193 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
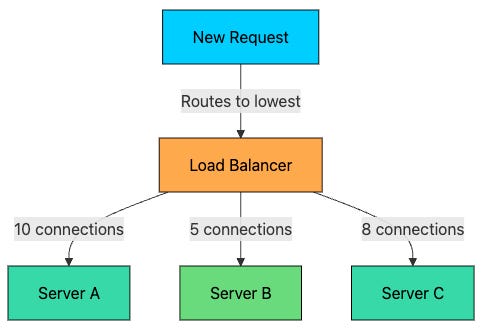
Learn how load balancers really work under the hood
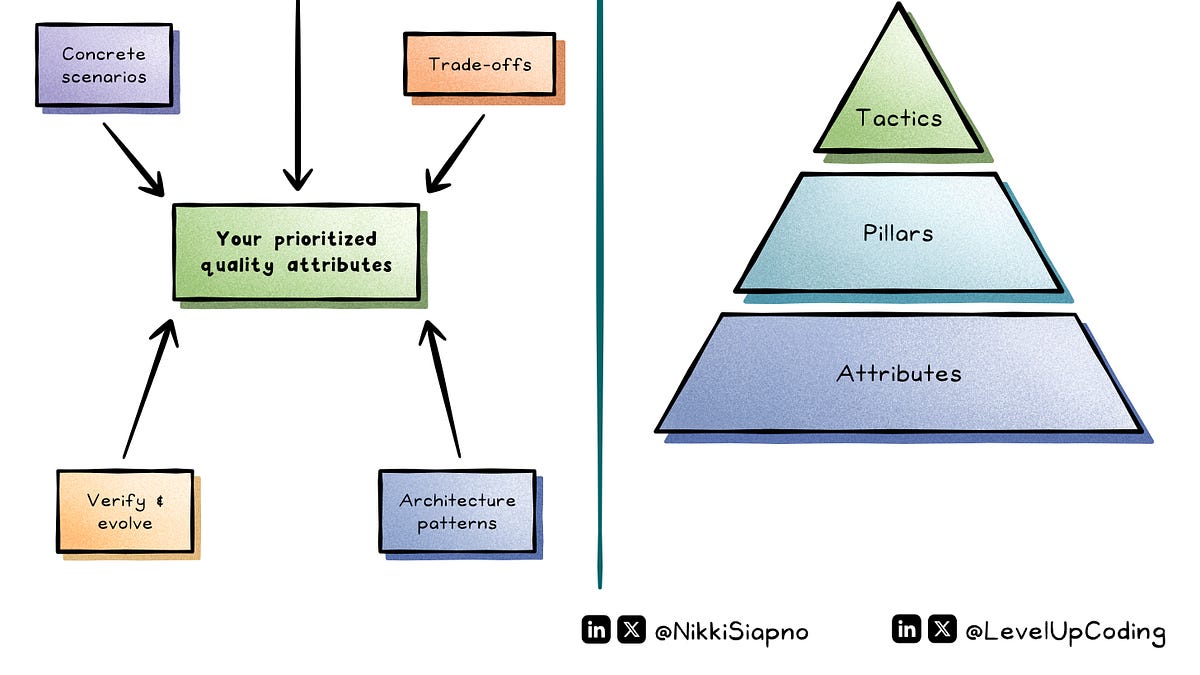
Must-know system design quality attributes explained simply
Essential TypeScript handbook for modern developers
AI agents demystified: key differences from ChatGPT
Master software testing fundamentals in one guide
🗞️ Tech and AI Trends
Ex-Googler shares 21 career-changing lessons from 14 years
Revolutionary database trends that shaped 2025
Amazon VP reveals what actually gets engineers promoted
👨🏻💻 Coding Tip
Use PyTorch pinned memory to speed up GPU transfers by 3x
Time-to-digest: 5 minutes

Google's Tensor Processing Unit (TPU) revolutionized AI computing by processing matrix multiplications at unprecedented speed and efficiency. From powering AlphaGo's historic victory to running modern language models, TPUs represent a paradigm shift in hardware architecture specifically designed for deep learning.
The challenge: Building hardware that could handle exponential growth in AI computation demands while breaking free from traditional Von Neumann architecture limitations and Moore's Law slowdown.
Implementation highlights:
Systolic array design: 256x256 grid of multiply-accumulate units that passes data like a bucket brigade
Custom memory hierarchy: 24MB unified buffer and weight FIFO for efficient data staging
Specialized precision: BFloat16 format balancing range and precision for AI workloads
High bandwidth memory: Evolution from 34 GB/s to 7.4 TB/s for massive throughput
Inter-chip scaling: Direct chip-to-chip links enabling massive TPU Pods up to 9216 chips
Results and learnings:
92 trillion ops/second on first-gen TPU while consuming only 40 watts
15-30x speed improvement over contemporary GPUs for inference tasks
>90% silicon utilization for computation vs ~30% in GPUs
The TPU proves that sometimes the best solution is to do one thing extremely well rather than many things adequately. By focusing purely on matrix multiplication, Google created a chip that transformed AI computing.


ARTICLE (bot-detective)
How Dependabot Actually Works
ARTICLE (future-peek)
Agentic AI, MCP, and spec-driven development: Top blog posts of 2025
GITHUB REPO (ai-patterns-party)
Awesome Agentic Patterns
GITHUB REPO (typescript-bible)
The Concise TypeScript Book
ARTICLE (postgres-whisperer)
Introducing pgX: Bridging the Gap Between Database and Application Monitoring for PostgreSQL
ESSENTIAL (test-or-die)
Software Testing Fundamentals Every Developer Should Understand
ESSENTIAL (no-vibes-just-design)
Vibe Coding Without System Design is a Trap
ARTICLE (brain-sparkles)
How to Think Creatively
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: Google engineer Addy Osmani reveals 21 crucial insights from his 14-year tenure, emphasizing that success in tech careers depends more on people skills, problem-solving, and organizational navigation than just coding abilities.
Brief: PostgreSQL continues to dominate as major players like Databricks and Snowflake make billion-dollar acquisitions, while Larry Ellison becomes world's richest person as Oracle's stock soars and database industry sees unprecedented M&A activity.
Brief: Developer Burke Holland demonstrates Claude Opus 4.5's remarkable capabilities by building four complex applications with minimal human intervention, suggesting AI agents could realistically replace developers as the model handles everything from coding to debugging with unprecedented accuracy.
Brief: Former Amazon VP Ethan Evans shares insights on what gets engineers promoted, highlighting five crucial traits: shipping complete products, making organizations faster, doing operational work, growing others, and anticipating problems, emphasizing that business impact matters more than just technical excellence.
Brief: Developer shows how to build a basic coding assistant similar to Claude using just 200 lines of Python code, implementing core functionalities like file reading, listing, and editing through a simple LLM-powered tool system.

This week’s coding challenge:
This week’s tip:
Use PyTorch's pinned memory allocation for faster GPU transfers by avoiding the default pageable memory bottleneck. Pinned memory allows direct memory access (DMA) transfers without CPU involvement, reducing transfer latency by 2-3x.

Wen?
Large dataset training: When loading batches >100MB where GPU transfer time exceeds computation time
Multi-GPU setups: Overlapping data transfers with computation using non_blocking=True across multiple devices
Real-time inference: Minimizing latency in production serving where microseconds matter for user experience
People who say it cannot be done should not interrupt those who are doing it. George Bernard Shaw


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).