
Today’s issue of Hungry Minds is brought to you by:


Happy Monday! ☀️
Welcome to the 489 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.
This week I also include a special recommendation newsletter if you want to learn system design with visuals 👇

📚 Software Engineering Articles
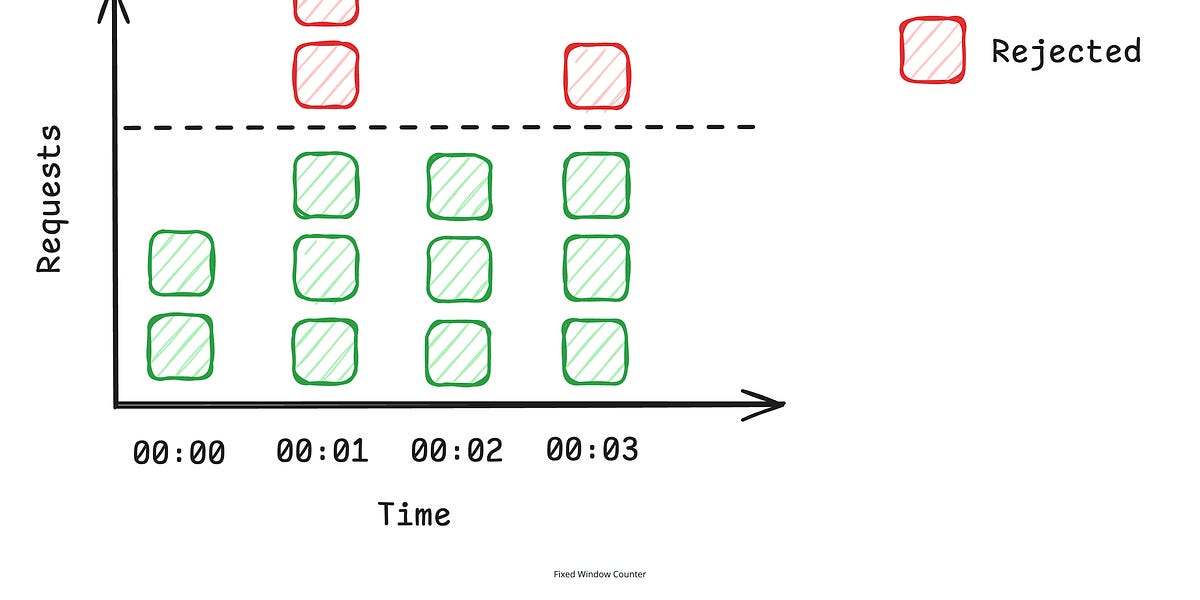
Learn how a rate limiter works with this practical system design guide
Build the world's fastest VIN decoder from scratch
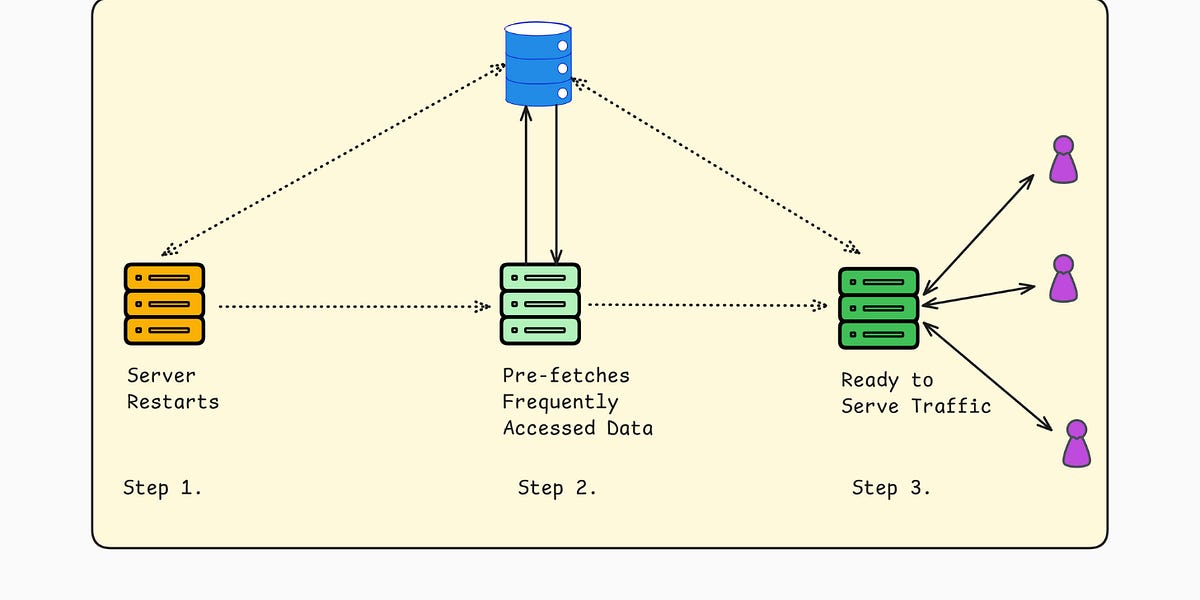
Smart cache warming strategies to boost application performance
How to handle duplicates in retry mechanisms
N+1 query problem explained and solved in 4 minutes
🗞️ Tech and AI Trends
Reddit transforms into a search engine powerhouse
Anthropic blocks OpenAI from accessing Claude models
Google launches Gemini Deep Think for parallel reasoning
👨🏻💻 Coding Tip
Use partial indexes in PostgreSQL to optimize query performance and reduce storage
Time-to-digest: 5 minutes
Big thanks to our partners for keeping this newsletter free.
If you have a second, clicking the ad below helps us a ton—and who knows, you might find something you love. 💚

Bitbucket Pipelines is not just a tool, it’s a DevOps force multiplier.
Unlock cloud-native CI/CD with 70% reduction in operational costs, no installation or plugins to manage, and efficient autoscaling.
Let engineers focus on delivering value – not maintaining Jenkins.

Searching through thousands of unlabeled images and videos is a nightmare for knowledge workers. Dropbox tackled this by building a scalable multimedia search system that makes finding visual content as easy as finding text documents in their universal search product, Dash.
The challenge: Build a cost-effective system that can process and search through massive amounts of media files while maintaining low latency and high relevance, despite limited metadata and heavy compute requirements.
Implementation highlights:
Metadata-first indexing: Extract lightweight features first (file paths, EXIF data) to enable basic search with minimal overhead
Just-in-time previews: Generate previews on-demand rather than upfront to optimize storage and compute costs
Location-aware queries: Built custom geocoding logic to enable searching by location where photos were taken
Parallel processing: Run preview generation, ranking, and permission checks concurrently to minimize latency
Smart caching: Store previews for 30 days and leverage existing Dropbox infrastructure for efficiency
Results and learnings:
Scalable performance: Successfully processes 97% of media files while maintaining responsive search
Cost optimization: Achieved 3x storage efficiency for images and 13x for video compared to raw storage
Developer velocity: Parallel workflows and clear API boundaries enabled faster team execution
This solution shows how thoughtful architecture decisions around caching, parallel processing, and metadata extraction can make multimedia search both performant and cost-effective.




ESSENTIAL (testing gone wrong)
The #1 Mistake in Unit Testing (and How to Fix It)
ESSENTIAL (retry, retry, oops)
Retries Have an Evil Twin: Duplicates
ESSENTIAL (metrics go brrr)
Essential System Design Performance Metrics
ARTICLE (vim-wizardry unlocked)
Why I Switched to Vim Keybindings
GITHUB REPO (trade like a boss)
A high-performance algorithmic trading platform and event-driven backtester
ARTICLE (database drama solved)
What is the N+1 Query Problem and How to Solve it?
ARTICLE (claude’s coding spree)
6 Weeks of Claude Code
ARTICLE (chrome goes zoom)
Making Sense of the Performance Extensibility API
ARTICLE (AI hype debunked)
No, AI is not Making Engineers 10x as Productive
ARTICLE (flashy list magic)
FlashList v2: A Ground-Up Rewrite for React Native's New Architecture
Want to reach 190,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

Brief: Reddit is working on a unified search interface as part of its strategy to compete with dominant search engines, potentially leveraging its vast community-driven content for better results.
Brief: Anthropic has revoked OpenAI’s access to its Claude AI models amid an escalating legal dispute, leaving OpenAI to seek alternatives for its AI research and services.
Brief: Google introduces Gemini DeepThink, an AI model designed to evaluate multiple ideas simultaneously, enhancing reasoning and problem-solving efficiency.
Brief: OpenAI releases gpt-oss-120b and gpt-oss-20b, two open-weight models under Apache 2.0 license, designed for agentic tasks, customization, and commercial use with full chain-of-thought reasoning.
Brief: OpenAI's GPT-5 offers three model tiers (regular, mini, nano) with competitive pricing and reduced hallucinations, making it a strong contender in the AI race.
Brief: AWS adds OpenAI’s open-weight GPT-OSS-120B and GPT-OSS-20B models to Bedrock and SageMaker, enabling developers to build AI applications with full infrastructure control and advanced reasoning capabilities.

This week’s coding challenge:
This week’s tip:
Create efficient database indices by using partial indexes with WHERE clauses to significantly reduce index size and improve query performance on specific data subsets. PostgreSQL's partial indices allow you to create smaller, more focused indexes that only include rows matching certain conditions.

Wen?
Large tables with skewed data: When certain status values represent a small, frequently-queried subset of all rows.
Time-series data management: Index recent data more aggressively while maintaining lighter indices for historical data.
Multi-tenant systems: Create focused indices for high-traffic customers while keeping the overall index footprint manageable.
“The harder you work, the harder it is to surrender.”
Vince Lombardi


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).