

Happy Monday! ☀️
Welcome to the 655 new hungry minds who have joined us since last Monday!
If you aren't subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
How Amazon uses LLMs to recommend products by building a commonsense knowledge graph
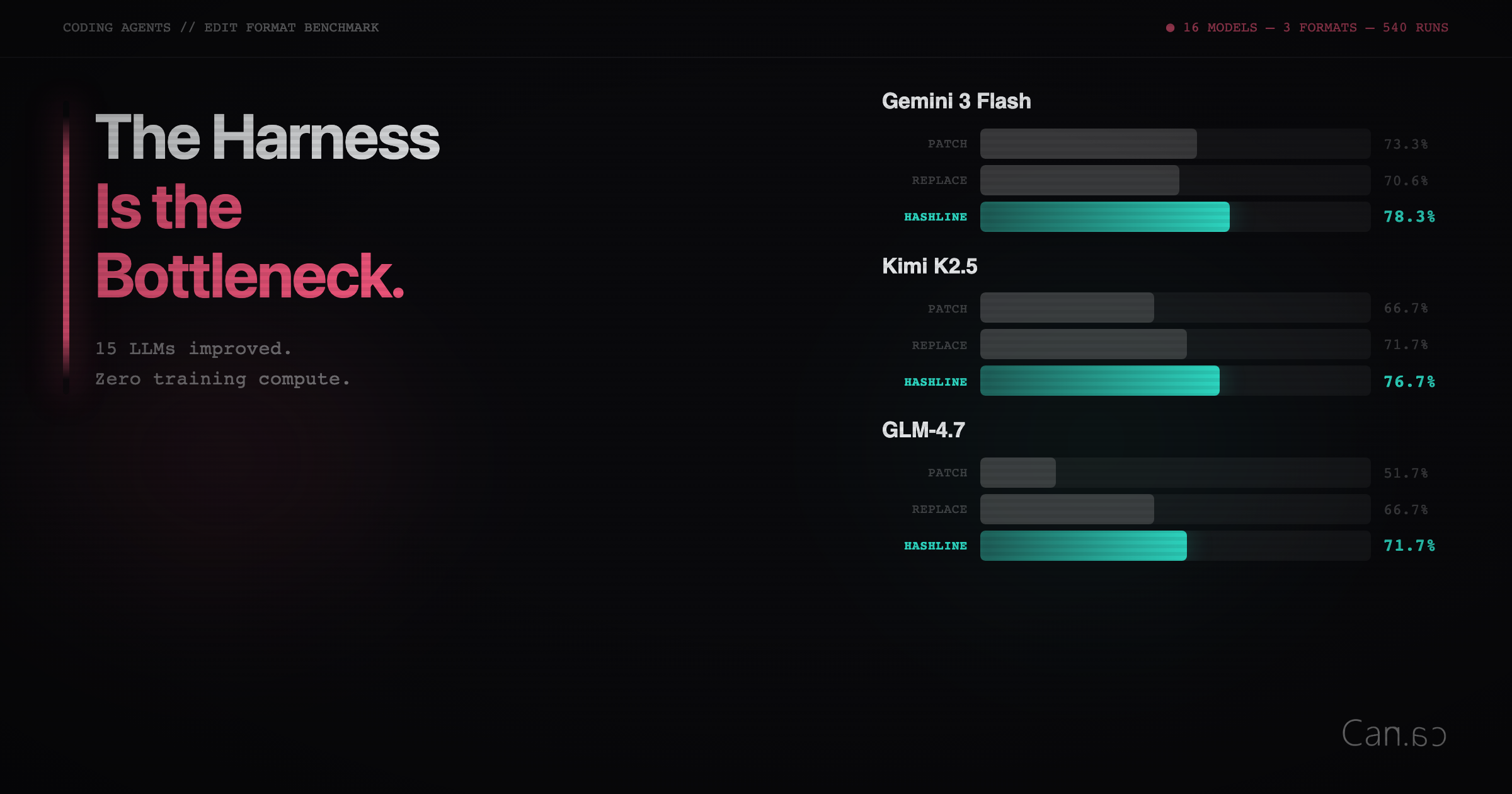
Agent harness engineering the system around the model matters more
The peril of laziness lost LLMs lack the virtue that makes good software
🗞️ Tech and AI Trends
PyTorch Lightning compromised in supply chain attack stealing credentials on import
Mistral launches Medium 3.5 with cloud coding agents and Work mode
Vercel breached via Context.ai — customer data sold for $2M
👨🏻💻 Coding Tip
Use ripgrep to search at lightspeed
Time-to-digest: 5 minutes

Search "shoes for pregnant women" on Amazon and the best results are slip-resistant shoes—even though the word "pregnant" appears nowhere in those listings. Traditional recommendation systems match keywords and purchase history, but when a shopper's intent requires a reasoning step that lives entirely in human common sense, those systems hit a wall. Amazon built COSMO, a commonsense knowledge graph that teaches the recommendation engine to think the way a human shopper would.
The challenge: Factual knowledge graphs encode what a product is (brand, color, material), but not why a human would want it. A query like "winter clothes" implies warmth, but no product listing says "this coat is warm." You need structured commonsense knowledge at e-commerce scale—and it didn't exist.
Implementation highlights:
LLM-as-ore-mine generation: Fed 5M+ behavior pairs (query→purchase and co-purchase) into OPT-175B hosted on internal infrastructure (data privacy constraint). The LLM generated millions of candidate explanations, but only 35% of search-buy and 9% of co-purchase explanations met quality bars—the rest were circular or trivially obvious
Multi-stage filtration pipeline: Rule-based filters removed incomplete or parroted text; embedding similarity filters caught semantic paraphrases; 30K human annotations evaluated plausibility and typicality via 5 decomposed yes/no questions; DeBERTa-large classifiers generalized those judgments to all remaining candidates
Data-driven ontology: Instead of designing relations top-down, Amazon mined 15 relation types from recurring LLM output patterns (used_for_function, used_for_audience, used_in_location, etc.), then canonicalized them into a structured schema
COSMO-LM distillation: Instruction-tuned LLaMA 7B/13B on the annotated data across 18 domains, 15 relations, and 5 tasks—collapsing the "big LLM + classifier" stack into a single smaller model that both generates and self-evaluates knowledge
Two-tier serving architecture: Pre-loaded cache covers frequent searches; daily batch processing handles newer queries. SageMaker manages model refresh from daily session logs, feeding Search Relevance, Recommendation, and Navigation simultaneously
Results and learnings:
30K annotations → 29M knowledge graph edges: The leverage ratio across 18 product categories, achieved through heavy investment in sampling, annotation design, and classifier training rather than brute-force labeling
Beat KDD Cup 2022 leaderboard: COSMO-augmented cross-encoder hit 73.48% Macro F1 and 90.78% Micro F1 on the public ESCI dataset, surpassing the top ensemble model. Frozen-encoder ablation showed a 60% Macro F1 lift from COSMO triples alone
0.7% relative sales increase → hundreds of millions in revenue: A/B tested on ~10% of U.S. traffic over several months, with an 8% navigation engagement lift—from a single small feature on the search page. Projected billions in revenue if extended across all traffic
Amazon proved that LLMs are powerful hypothesis generators but terrible oracles. COSMO works because the engineering effort went into filtration; throwing away 91% of co-purchase explanations. The system's daily refresh means it can't react to flash sales, and aggressive plausibility thresholds leave gaps in long-tail coverage, but Amazon chose precision over recall because unreliable commonsense in production is worse than missing knowledge.




ARTICLE (trust your agent, lose your data)
An AI Agent Just Destroyed Our Production Data
ARTICLE (the CIA had a .bashrc too)
Cleaning Up Merged Git Branches: A One-Liner From the CIA's Leaked Dev Docs
ARTICLE (AI agent PRs a blog post roasting the maintainer) matplotlib/matplotlib#31132
ARTICLE (six phases from chatbot skeptic to overnight delegation)
My AI Adoption Journey — Mitchell Hashimoto
ARTICLE (laziness as a virtue, continued)
Laziness, Impatience, and Hubris — Adam Jacob
ESSENTIAL (laws that explain why your project is late)
The 20 Software Engineering Laws
GITHUB (agent skills from Google's eng culture)
addyosmani/agent-skills
GITHUB (the .claude directory everyone is forking)
mattpocock/skills
GITHUB (Karpathy's CLAUDE.md in one file)
forrestchang/andrej-karpathy-skills
GITHUB (adaptive scraping that handles anti-bot like it's 2016)
D4Vinci/Scrapling
Want to reach 200,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

🔒 Vercel Breached via Third-Party AI Tool — Customer Credentials Stolen and Sold for $2M (3 min)
Brief: Hackers compromised Context.ai, a third-party AI tool used by a Vercel employee who had granted it OAuth access to their Google Workspace. The attackers pivoted from that foothold into Vercel's internal systems, accessing environment variables that weren't encrypted at rest. Stolen data appeared for sale on BreachForums at $2M. Vercel says Next.js and Turbopack were unaffected, but the incident is a textbook example of OAuth supply chain trust gone wrong.
☁️ Cloudflare and Stripe Launch Protocol That Lets AI Agents Create Accounts, Buy Domains, and Deploy (4 min)
Brief: Cloudflare and Stripe co-designed a new protocol that lets AI agents autonomously discover services, provision accounts, purchase domains, and deploy apps—all within a single agent session with zero human pre-configuration. If no Cloudflare account exists, one is created automatically. The protocol uses OAuth extended with payments and account creation, treating agents as first-class citizens. Any platform can integrate the same way Stripe does.
🤖 Google Releases Gemini 3 Flash — Pro-Grade Reasoning at Flash Speed and a Fraction of the Cost (2 min)
Brief: Google shipped Gemini 3 Flash, which outperforms Gemini 2.5 Pro while being 3x faster at $0.50/1M input tokens. It hits 78% on SWE-Bench Verified in Gemini CLI—beating even Gemini 3 Pro on agentic coding—and uses 30% fewer thinking tokens than 2.5 Pro on everyday tasks. It's now the default model in the Gemini app and AI Mode in Search, with two toggle modes: "Fast" for low-latency chat and "Thinking" for complex reasoning.
🔒 Critical GitHub RCE Flaw Lets Authenticated Users Execute Code via a Single Git Push (2 min)
Brief: CVE-2026-3854 is a high-severity remote code execution vulnerability in GitHub Enterprise Server where an authenticated user with push access could trigger arbitrary code execution through a crafted git push. GitHub patched it quickly with no evidence of pre-disclosure exploitation, but the flaw puts private repos, secrets, and deployment scripts at risk for any self-hosted GHES instance that hasn't updated.
🤖 OpenAI Drops Microsoft Exclusivity — Can Now Sell Across AWS and Google Cloud (2 min)
Brief: OpenAI quietly rewrote its deal with Microsoft to sell models and API access directly through AWS and Google Cloud, ending years of Azure exclusivity. The move lets enterprise customers run OpenAI models on their existing cloud provider without migration, dramatically expanding OpenAI's addressable market while signaling that no single cloud giant can lock in the AI API layer.
🤖 Google I/O 2026 Set for May 19–20 With "Agentic Era" Focus (1 min)
Brief: Google I/O returns May 19–20 with a keynote centered on the "agentic era" of development. Expect major updates across Android, AI, Chrome, and Cloud, with the event focused on new tools designed to automate complex workflows and simplify building AI-ready applications. Gemini 3.2 Flash has already been spotted testing on Eleuther AI Arena ahead of the event.

This week’s tip:
Leverage ripgrep's --type and --glob patterns with FPAT-like regex for multi-line matching without loading files into memory. ripgrep is orders of magnitude faster than grep/awk for code search, especially when combined with --multiline (-U) and --max-columns to handle generated or minified code safely.

Wen?
Searching across large TypeScript/Rust codebases for async/await patterns: ripgrep's memory-mapped I/O and parallel search by default beats grep even with xargs -P.
Finding multi-line regex in JSON config or log files: Use --multiline with lookahead to avoid OOM on huge files.
Narrow search scope before slow operations: Combine with --files-with-matches -c to get counts first, then feed results to parallel processing tools like GNU parallel.
It’s always day one.
Jeff Bezos


That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).